안녕하세요. [code_sticker]입니다.
파이썬 코딩 학습을 시작하고 첫 실전 프로그램인 네이버 주식 정보 자동 크롤링 프로그램을 만들어보았습니다.
네이버 증권 웹페이지에서 내가 원하는 항목의 데이터만 크롤링하여 엑셀에 담아주는 프로그램이고요.
2부에 걸쳐 공부한 코드를 설명과 함께 소개해드리겠습니다.
겨우겨우 파이썬 기본 문법 강좌만 듣고 따라 하는 거라 중간에 무진장 헤맸지만
결국 잘 돌아가니 뿌듯했고 빅 재미를 느껴버렸습니다.
다만, 제가 전공자나 전문가가 아닌 입문자라 설명에 오류가 있거나 틀린 부분이 있으면
댓글에 지도, 첨삭 부탁드립니다.
저에게 굉장히 큰 도움이 될 것입니다. ^^;
그럼 직접 코드를 살펴보면서 설명을 좀 드려보겠습니다.
먼저 실제 프로그램이 작동하는 모습을 보실까요?
프로그램의 동작 순서를 보면...
1. 웹 브라우저가 켜지면서 네이버 주식 페이지에 접속하고,
2. 기본으로 선택되어 있는 항목의 체크를 해제한 뒤,
3. 내가 보고 싶은 항목에 다시 체크하여 적용 버튼을 눌러 결과를 보여준다.
4. 그렇게 여러 페이지에 걸쳐 표시된 데이터들을 엑셀로 담아 저장한다.
입니다. 간단하죠?
이렇게 얻은 데이터들은 하나의 엑셀파일에서 다양하게 가공하여 활용할 수 있습니다.
1. 패키지, 모듈 import / 브라우저 웹 드라이버 사용
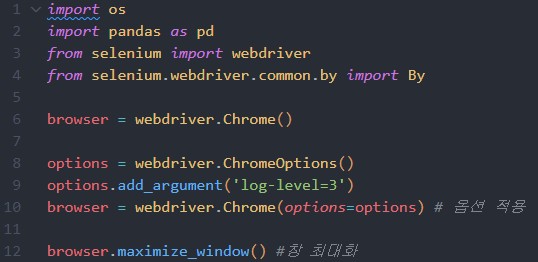
첫 번째 코드 단락을 보겠습니다.
여러 가지 패키지, 모듈을 먼저 가져와야겠지요?
import os
- 운영체제와 파이썬 간의 상호작용을 돕습니다.
- 엑셀 파일을 생성하고 저장하는 데 사용됩니다.
import pandas as pd
- pandas 패키지를 임포트하고 pd라는 이름으로 사용하겠다는 뜻입니다.
- 유명한 데이터 분석 라이브러리입니다. 머신러닝에서 데이터를 관리하는데 아주 중추적인 역할을 하는 패키지죠.
- 데이터를 표 형태의 공간에 넣어서 쉽게 이용할 수 있게 해 줍니다.
- 파이썬의 엑셀이라고 생각하시면 이해가 좀 편하실 거예요.
from selenium import webdriver
- selenuim 패키지에서 webdriver 모듈을 임포트 해 사용하겠다는 뜻입니다.
- selenium은 웹사이트 테스트 도구로써 프로그래밍으로 브라우저 동작을 제어하여
- 마치 사람이 이용하는 것 같이 웹페이지를 요청하거나 응답할 수 있게 해 주고요.
- webdriver는 사용하고자 하는 브라우저를 조종하는 기능이 있나 봅니다.
- 참고로 PC에 사용하시는 웹 브라우저의 종류와 버전이 일치하는 webdriver를 먼저 설치하셔야 합니다.(필수!)
from selenium.webdriver.common.by import By
- selenium 안에 webdriver 안에 common 안에 by라는 곳에서 By를 임포트 하겠다는 뜻입니다.
- 특정 element를 검색할 때 어떤 방식으로 찾을지 알려주는 기능을 합니다.
- 이를테면, 태그명으로 찾겠다! 아니면 path로 찾겠다! 하고 뒤에 태그명이나 경로를 적어주는 거죠.
browser = webdriver.Chrome()
- browser라는 변수에 webdriver의 Chrome() 함수를 실행시켜 브라우저를 켭니다.
options = webdriver.ChromeOptions()
options.add_argument('log-level=3')
browser = webdriver.Chrome(options=options)
- 크롬 객체를 생성할 때 로그 레벨 설정을 통해 불필요한 로그는 표시되지 않도록 해주는 코드입니다.
- option의 레벨을 3단계로 설정하여 강제적으로 오류를 무시하게 하는 코드인 것 같습니다.
browser.maximize_window()
- 앞서 실행시킨 웹 브라우저의 창을 최대화합니다.
2. 네이버 주식 정보 체크 해제 > 원하는 항목 선택 > 결과 표시

두 번째 코드 단락은 네이버 주식 페이지로 접속하여
1. 기존 선택된 항목을 해제하고
2. 내가 원하는 항목을 새로 체크한 뒤,
3. 결과를 표시하는 코드입니다.
url = 'https://finance.naver.com/sise/sise_market_sum.naver?sosok=0&page='
browser.get(url)
- url 변수에 접속할 페이지 주소를 담아
- 앞서 생성한 browser의 get() 함수에 넣어 접속을 가능하게 해 줍니다.
checkboxes = browser.find_elements(By.NAME, 'fieldIds')
- 웹페이지의 html 태그를 분석하여 NAME 속성이 fieldIds인 녀석들을 browser.find_elements() 함수를 이용해 모조리 찾아 checkboxes 변수에 저장합니다.
- 웹페이지 html 태그의 NAME 속성이 fieldIds인 녀석들이 체크박스들입니다.
- 그 녀석들을 모두 찾아서 가져오라는 뜻이죠.
- 그리고 find_elements() 함수는 리스트 형식을 반환하기에 checkboxes 변수도 리스트이게 됩니다.
for checkbox in checkboxes:
if checkbox.is_selected(): # 체크된 상태라면?
checkbox.click() # 클릭해서 체크를 해제
- for 반복문으로 가져온 체크박스들을 하나씩 꺼내
- 체크가 되어 있는지 아닌지 검사를 하고
- 체크가 되어 있다면 클릭해서 체크를 해제합니다.
- is_selected() 함수는 글자 그대로 셀렉트 되어있으면 True를 반환하여
- 다음 코드인 click() 함수를 실행해 체크가 해제됩니다.
items_to_selected = ['시가총액', '매출액', '영업이익', 'PER', 'ROE', 'PBR']
- 내가 보고 싶은 내용의 체크박스 이름을 item_to_selected 변수에 리스트로 저장합니다.
for checkbox in checkboxes:
parent = checkbox.find_element(By.XPATH, '..') # 부모 element를 찾아라!
label = parent.find_element(By.TAG_NAME, 'label')
if label.text in items_to_selected: # 선택항목과 일치한다면?
checkbox.click() # 체크
- for 문으로 checkboxes 안에 담긴 체크박스를 하나씩 꺼내어 checkbox 변수에 담고 이후 코드를 진행하게 됩니다.
- checkbox의 find_element() 함수로 부모(상위) element를 찾아 parent 변수에 담습니다. By.XPATH가 의미하는 것은 찾는 방식은 html의 경로를 이용한다라고 하는 거고요. '..'가 자신의 바로 상위 element의 경로를 의미합니다. 왜 상위 element를 찾아 변수에 담느냐? 상위 element를 찾고 거기서 태그명 label을 찾아야지 현재 선택된 checkbox 자신에게서 find_element() 함수를 사용해 태그명 label을 찾아봤자 본인의 label만 보일뿐 내가 선택하고자 하는 label과 비교가 불가능합니다.
- 부모단의 위치에서 태그명이 label인 것을 찾아 label 변수에 담습니다.
- 그리고 내가 보고 싶은 항목의 이름을 저장한 리스트(item_to_selected)에서 값을 하나씩 꺼내 label의 text와 비교한 뒤, 일치하면 그 checkbox를 클릭하여 선택하게 합니다.
btn_apply = browser.find_element(By.XPATH, '//a[@href="javascript:fieldSubmit()"]')
btn_apply.click()
- btn_apply 변수에 최초 웹페이지의 모든 정보를 담고 있는 browser 변수에서 find_element() 함수로 html 경로가 '//a[@href="javascript:fieldSubmit()"]' 인 것을 찾아 저장합니다. <-- 이게 바로 적용하기 버튼을 가리킵니다.
- 그리고 click() 함수로 적용하기 버튼을 클릭하게 합니다.
이렇게 해서 주식 정보 크롤링 프로그램의 코드 설명 1부를 마치도록 하겠습니다.
제가 이해한 수준에서 최대한 설명을 해보려고 했는데 아직 코드에 대한 이해도가 많이 부족해서인지
조금 난해한 부분이 있는 점 이해 부탁드립니다.
앞서 말씀드린 것과 같이 잘못된 부분이나 조언해 주실 부분은 댓글로 꼭 좀 부탁드리고요.
혹시 궁금한 사항이 있다면 역시 댓글 남겨주세요. 아는 한도에서 성실히 답변드리겠습니다.
빠른 시일 내에 2부마저 올리도록 하겠고요.
끝까지 글 읽어주셔서 정말로 감사합니다.
좋은 하루 되세요.~

'오늘' 카테고리의 다른 글
| [파이썬 실전] 네이버 주식 웹페이지 크롤링 프로그램 만들기 [2/2] (0) | 2022.10.19 |
|---|---|
| [파이썬] 웹 스크래핑을 공부하게 된 이유! (0) | 2022.10.18 |
| [파이썬 배우기 기본편] 01. 개발 환경 구축하기 (0) | 2022.10.14 |
| 백수 아빠의 파이썬 프로그래밍 도전 시작 (0) | 2022.10.13 |
| 넷플릭스 '본능의 질주' 시즌 4 꿀잼 (포뮬러1/Formula 1/F1) (0) | 2022.09.16 |




댓글